What does event-driven data science even look like??
In this tutorial we’ll find out! Join along for a tour of implementing an event-driven Natural Language Processing tool that does streaming HTML parsing, entity extraction, and sentiment analysis.
Just here for the code? Check it out here!
Back to the Future
Some of the earliest deployed machine learning apps were event-driven.
Spam filtering is an awesome example of a natural use case for online modeling. Each newly flagged spam message was a new training event, an opportunity to update the model in real time. While most machine learning bootcamps teach us to expect data in batches, there are a TON of natural use cases for streaming data science (maybe even more than for offline aka batchwise modeling!).
Another great use case for event-driven data science is Natural Language Processing tasks such as:
- named entity recognition
- text classification
- sentiment analysis
In this tutorial, we’ll tap into a live data feed and see how to process the text content as it streams in.
A Whale of a Problem
Baleen is a project incubated at Rotational Labs for building experimental corpora for Natural Language Processing
Baleen works on a schedule; every hour it fetches news articles from public RSS feeds and stores them to Ensign. Baleen’s Ensign Publisher stores each news article as an event in a topic stream called documents. You can think of a topic stream like a database table in a traditional relational database.
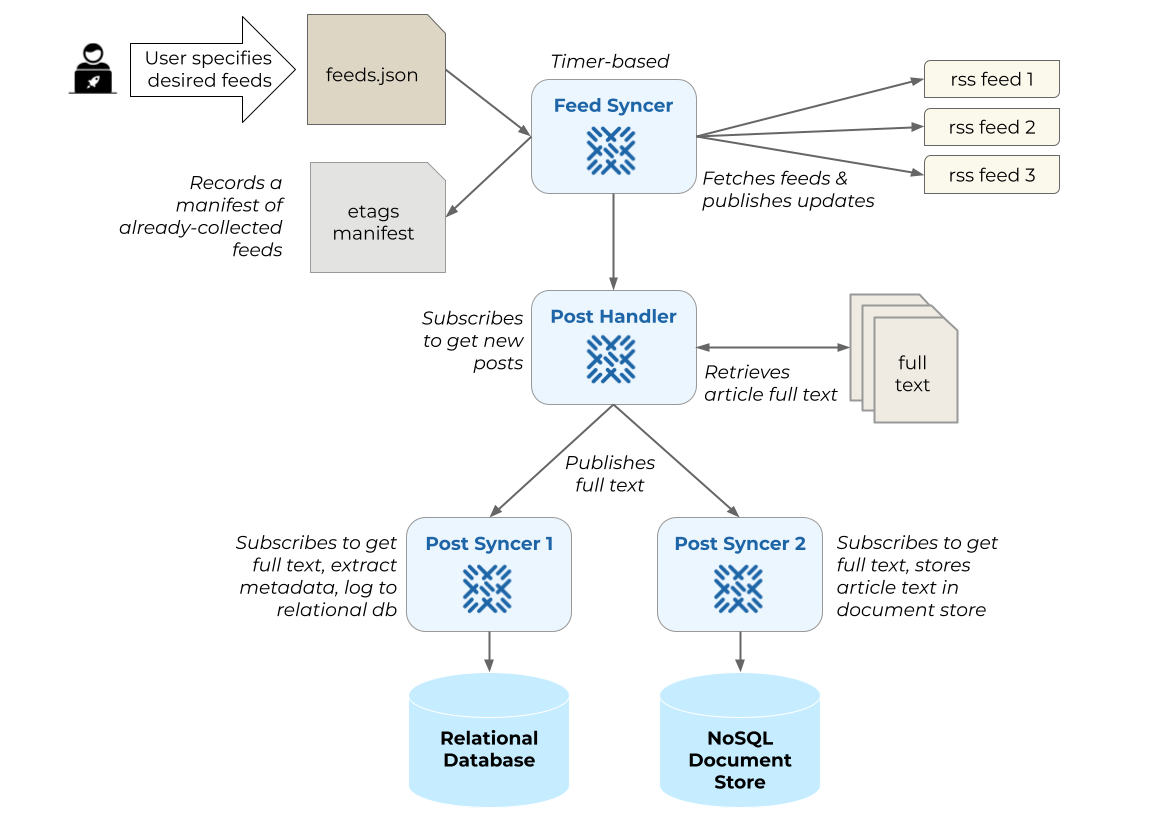
Our app is going to read off of that documents stream using an Ensign Subscriber to perform and report analytics on the text of each article as soon as it was published.
Creating our Ensign Subscriber
We can write a Subscriber to connect to the Baleen documents topic feed in order to tap into the stream of parsed RSS news articles:
class BaleenSubscriber:
"""
Implementing an event-driven Natural Language Processing tool that
does streaming HTML parsing, entity extraction, and sentiment analysis
"""
def __init__(self, topic="documents", ensign_creds=""):
"""
Initialize the BaleenSubscriber, which will allow a data consumer
to subscribe to the topic that the publisher is pushing articles to
"""
self.topic = topic
self.ensign = Ensign(
cred_path=ensign_creds
)
self.NER = spacy.load('en_core_web_sm')
The next step is to add a subscribe method to access the topic stream:
async def subscribe(self):
"""
Subscribe to the article and parse the events.
"""
id = await self.ensign.topic_id(self.topic)
async for event in self.ensign.subscribe(id):
await self.parse_event(event)
And another method to run the subscribe method in a continuous loop:
def run(self):
"""
Run the subscriber forever.
"""
asyncio.run(self.subscribe())
If we were to run the BaleenSubscriber now, e.g. with this if-main block:
if __name__ == "__main__":
subscriber = BaleenSubscriber(ensign_creds = 'secret/ensign_creds.json')
subscriber.run()
Note: This code assumes you have defined a JSON file with your Ensign API key credentials at secret/ensign_creds.json, however you can also specify your credentials in the environment
… you’d see your terminal run the command and just… wait!
Don’t worry, that’s normal. The job of an Ensign Subscriber is to do exactly that; it will come online and just wait for an upstream Publisher to start sending data.
Once it’s running, our BaleenSubscriber will wait until the next batch of RSS feeds is available.
NLP Magic Time
Now it’s time to write the fun data science parts!
In this section, we’ll add some functionality for text processing, entity recognition, and sentiment analysis so that these tasks are performed in real time on every new RSS document published to the documents feed.
We’ll write this as a function called parse_event. The first step is to unmarshal each new document from MessagePack format into json (the Baleen application publishes documents in msgpack because it’s more efficient!):
async def parse_event(self, event):
"""
Decode the msgpack payload, in preparation for applying our NLP "magic"
"""
try:
data = msgpack.unpackb(event.data)
except Exception:
print("Received invalid msgpack data in event payload:", event.data)
await event.nack(Nack.Code.UNKNOWN_TYPE)
return
# Parse the soup next!
Parsing the Beautiful Soup
The first step in all real world text processing and modeling projects (well, after ingestion of course ;-D) is parsing. The specific parsing technique has a lot to do with the data; but in this case we’re starting with HTML documents, which is what Baleen’s Publisher delivers.
We’ll use the amazing BeautifulSoup library:
async def parse_event(self, event):
"""
Decode the msgpack payload, in preparation for applying our NLP "magic"
"""
try:
data = msgpack.unpackb(event.data)
except json.JSONDecodeError:
print("Received invalid JSON in event payload:", event.data)
await event.nack(Nack.Code.UNKNOWN_TYPE)
return
# Parsing the content using BeautifulSoup
soup = BeautifulSoup(data[b'content'], 'html.parser')
# Finding all the 'p' tags in the parsed content
paras = soup.find_all('p')
Now we can iterate over paras to process each paragraph chunk by chunk.
More than a Feeling
Let’s say that we want to do streaming sentiment analysis so that we can gauge the sentiment levels of the documents right away rather than in a batch analysis a month from now, when it may be too late to intervene!
For this we’ll leverage the sentiment analysis tools implemented in textblob, iterating over the paras we extracted from the HTML in the section above and score the text of each using the pre-trained TextBlob sentiment model.
We could look at the sentiment of each paragraph, but for tutorial purposes we’ll just take an average sentiment for the overall article:
async def handle(self, event):
# ...
# ...
# Finding all the 'p' tags in the parsed content
paras = soup.find_all('p')
score = []
# ...
for para in paras:
text = TextBlob(para.get_text())
score.append(text.sentiment.polarity)
Let’s add an entity extraction step to our iteration over the paras using the excellent SpaCy NLP library. You first create a spacy.Document by passing in the text content to the pretrained parser (which we previously added to our BaleenSubscriber class with spacy.load('en_core_web_sm')). This invokes the entity parsing, after which you can iterate over the resulting entities (ents), which consist of tuples of the form (text, label).
# ..
# ..
ner_dict = {}
for para in paras:
ner_text = self.NER(str(para.get_text()))
for word in ner_text.ents:
if word.label_ in ner_dict.keys():
if word.text not in ner_dict[word.label_]:
ner_dict[word.label_].append(word.text)
else :
ner_dict[word.label_] = [word.text]
Finally, we’ll acknowledge that we’ve received the event and print out some feedback to ourselves on the command line so we can see what’s happening!
# ...
# ...
print("\nSentiment Average Score : ", sum(score) / len(score))
print("\n------------------------------\n")
print("Named Entities : \n",json.dumps(
ner_dict,
sort_keys=True,
indent=4,
separators=(',', ': ')
)
)
await event.ack()
Now, every time a new article is published, we’ll get something like this:
Sentiment Average Score : 0.05073840565119635
------------------------------
Named Entities :
{
"CARDINAL": [
"two",
"one",
"five",
"18",
"2"
],
"DATE": [
"recent months",
"Friday",
"her first day",
"four years",
"March",
"The next month",
"this week",
"Saturday",
"the next two days"
],
"FAC": [
"the Great Hall of the People",
"Tiananmen Square"
],
"GPE": [
"U.S.",
"China",
"the United States",
"Beijing",
"Shanghai",
"The United States",
"Washington",
"Hong Kong",
"Detroit"
],
"NORP": [
"American",
"Chinese",
"Americans"
],
"ORDINAL": [
"first"
],
"ORG": [
"Treasury",
"the Treasury Department",
"the American Chamber of Commerce",
"Boeing",
"Bank of America",
"the Mintz Group",
"Bain & Company",
"TikTok",
"ByteDance",
"the Center for American Studies at",
"Peking University",
"Renmin University",
"The U.S. State Department",
"the Chamber of Commerce",
"the People\u2019s Bank of China",
"Treasury Department",
"CCTV",
"The Financial Times",
"The Times"
],
"PERSON": [
"Janet Yellen",
"Alan Rappeport",
"Keith Bradsher",
"Janet L. Yellen",
"Yellen",
"Biden",
"Li Qiang",
"Cargill",
"Wang Yong",
"Wang",
"Shi Yinhong",
"Michael Hart",
"Hart",
"Liu He",
"Yi Gang",
"Li",
"Claire Fu",
"Christopher Buckley"
],
"TIME": [
"five hours",
"more than an hour",
"afternoon",
"over an hour"
]
}
Thanks to BeautifulSoup, TextBlob, SpaCy, and Ensign we now have:
- a live feed of RSS articles
- a way to parse incoming HTML text into component parts
- a way to score the sentiment of incoming articles
- a way to extract entities from those articles
What’s Next?
So many possibilities! We could create a live alerting system that throws a flag every time a specific entity is mentioned. We could configure those alerts to fire only when the sentiment is below some threshold.
Want to try your hand with real time NLP? Check out the Data Playground to look for interesting data sets to experiment with doing event-driven data science!
Reach out to us at info@rotational.io and let us know what else you’d want to make!
Breaking Free from the Batch
Applied machine learning has come a loooong way in the last ten years. Open source libraries like scikit-learn, TensorFlow, spaCy, and HuggingFace have put ML into the hands of everyday practitioners like us. However, many of us are still struggling to get our models into production.
And if you know how applied machine learning works, you know delays are bad! As new data naturally “drifts” away from historic data, the training input of our models becomes less and less relevant to the real world problems we’re trying to use prediction to solve. Imagine how much more robust your applications would be if they were not only trained on the freshest data, but could alert you to drifts as soon as they happen – you’d be able to react immediately as opposed to a batchwise process where you’d be lucky to catch the issue within a day!
Event-driven data science is one of the best solutions to the MLOps problem. MLOps often requires us to shoehorn our beautiful models into the existing data flows of our organizations. With a few very special exceptions (we especially love Vowpal Wabbit and Chip Huyen’s introduction to streaming for data scientists), ML tools and training teach us to expect our data in batches, but that’s not usually how data flows organically through an app or into a database. If you can figure out how to reconfigure your data science flow to more closely match how data travels in your organization, the pain of MLOps can be reduced to almost nil.
Happy Eventing!
